




教授
さかもと ひろし
インターネットの利用率が増加し、研究者や一部のユーザだけではなく、一般の人々もネットワーク上にデータを蓄積するようになり、従来の情報検索では、必要なデータにうまくアクセスできなくなりつつあります。
そこでこれからは、”ゴミ”と思われるデータをうまく選別して、いかに捨てるかという技術が必要になります。
これが現在の私の主要テーマです。
情報を捨てるための技術
① グラフの局所的構造に基づく大規模半構造データからの高速パターン発見
② データの更新に対して頑健・高速な半構造データからの情報抽出アルゴリズムの構築
③ 半構造テキストデータの一般構造を推論する高度情報抽出アルゴリズムの構築
ウエブマイニング、データベース、XML、索引構造
データを高速に検索したりマイニングするためには、データへ索引を付ける必要があります。しかし、GBを超える巨大テキストの索引構築は、必要な作業領域が大きく容易ではありません。そこで、圧縮されたデータから検索することが有望だと考えられます。ここで重要なのは、索引を圧縮するのではなく、圧縮データそのものを索引として使うということです。両者には必要とする作業領域に決定的な違いがあります。では、どのような圧縮をすれば索引として利用できるのでしょうか?
ここで圧縮法としての性質は、圧縮率よりも、原データの性質を保存することの方が重要です。データ圧縮の実用的なアルゴリズムは多数知られていますが、この性質を満足する理想的な手法は、まだ確立されていません。これを実現することで、巨大データから埋もれた重要情報を発掘できると考えています。
現在ネットワーク上に蓄積されている巨大なXML/HTMLデータは、リンク構造で結合された不均一なデータベースと見なすことができます。しかし、単にリンクを辿るだけでは、効率よく目的のデータにアクセスすることはできません。そこで、このようなグラフ構造に隠された部分構造を圧縮索引として補助的に用いることで、必要な情報にダイレクトにアクセスできる可能性があります。
(第1図 参照)
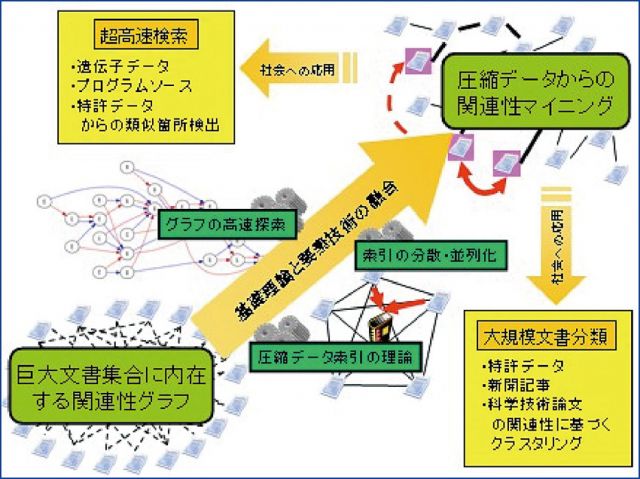
第1図・先生の研究概要
ウェブマイニング、大学など、研究機関との共同研究や受託研究を希望しています。
① 『A space-saving approximation algorithm for grammar-based compression』
IEICE Trans. on Information and Systems E92-D (2):158-165 (2009) H.Sakamoto, S.Maruyama, T.Kida, S.Shimozono
② 『有向グラフ上の到達可能性のための索引構造と大規模XMLデータベースへの応用』
電子情報通信学会論文誌 J91-D (9):2217-2224 (2008) 中村有作、原口新平、舞田哲 哉、坂本比呂志
③ 『有向グラフ上の最短経路問題に対する効率的な索引付け』
日本データベース学会論文誌、7巻、1号、pp.211-214 (2008) 原口新平、中村有作、坂本 比呂志
④ 『高速な到達可能性判定のための規模耐性の高い索引付け』
日本データベース学会Letters 6 (1):77-80 (2007) 中村有作、舞田哲哉、坂本比呂志

